
Get Up And Running With Regex In No Time (System Programming).
How Linux Regular Expression Command works (The Use of grep Command)


Introduction
In any search algorithm, we need something to pass to identify the complex string available in the input string or input data which is basically a sequence of characters or string that would define the searching pattern. A set of characters that help to effectively achieve this purpose is called Regular Expression or regex also called as regexp. The regular expression is nothing but a symbolic representation in the searching algorithm.
Regular expressions can be one of the most powerful tools in your toolbox as a Linux user, system administrator, or even as a programmer. It can also be one of the most daunting things to learn, but it doesn't have to be! While there are an infinite number of ways to write an expression, you don't have to learn every single switch and flag. In this short how-to, I'll show you a few simple ways to use regex that will have you running in no time and share some follow-up resources that will make you a regex master if you want to be.
Why We Need Regular Expressions
As mentioned above, regular expressions are used to define a pattern to help us match on or "find" objects that match that pattern. Those objects can be files in a filesystem when using the find command for instance, or a block of text in a file which we might search using grep, awk, vi, or sed, for example.
Start With The Basics
Let's start at the very beginning; it's a very good place to start.
The first regex everyone seems to learn is probably one you already know and didn't realize what it was. Have you ever wanted to print out a list of files in a directory, but it was too long? Maybe you've seen someone type *.gif to list GIF images in a directory, like:
silva@oluwaseunda-silva:~$ ls *.gif
That's a regular expression!
When writing regular expressions, certain characters have special meaning to allow us to move beyond matching just characters to matching entire sets of characters. In this case, the * character, also called "star" or "splat" takes the place of filenames and allows you to match all files ending with .gif.
Character Categories
In regex, we have two categories of characters.
Regular (Literal) characters: Literally any character as we use it in the English language.
Meta characters: These characters can be either special characters like
$or^and so on, or can be literal characters with a backslash in front of them like\dor\w. These characters carry a special meaning, for example,\dmatches a single digit in a text or^matches the beginning of a string.
Regular Expressions are not specific to Linux or any programming language and what is supported depends on the tool you use. In this article, we will cover Regular Expressions that can be used in a Unix/Linux environment.
Grep
Grep is an essential Linux and Unix command. It is used to search text and strings in a given file. In other words, grep command searches the given file for lines containing a match to the given strings or words. It is one of the most useful commands on Linux and Unix-like system for developers and sysadmins. Let us see how to use grep on a Linux or Unix like system.
grep command examples in Linux and Unix
Below are some standard grep commands explained with examples to get you started with grep on Linux, macOS, and Unix:
Search any line that contains the word in filename on Linux:
silva@oluwaseunda-silva:~$ grep 'word' filename
Perform a case-insensitive search for the word 'bar' in Linux and Unix:
silva@oluwaseunda-silva:~$ grep -i 'bar' file1
Look for all files in the current directory and in all of its subdirectories in Linux for the word 'httpd':
silva@oluwaseunda-silva:~/mydir$ grep -R 'httpd' .
Search and display the total number of times that the string 'nixcraft' appears in a file named frontpage.md:
silva@oluwaseunda-silva:~$ grep -c 'nixcraft' frontpage.md
Types of Regular Expressions
For ease of understanding let us learn the different types of Regex one by one.
- Basic Regular expressions
- Interval Regular expressions
- Extended regular expressions
1. Basic Regular Expressions
Listed below are some of the basic Regex symbols with descriptions.
Symbol Descriptions
. Replaces any character
^ Matches start of string
$ Matches end of string
* Matches up zero or more times the preceding character
\ Represent special characters
() Groups regular expressions
? Matches up exactly one character
Let us see some commands and options from this category in details with examples.

That's cool... Right?
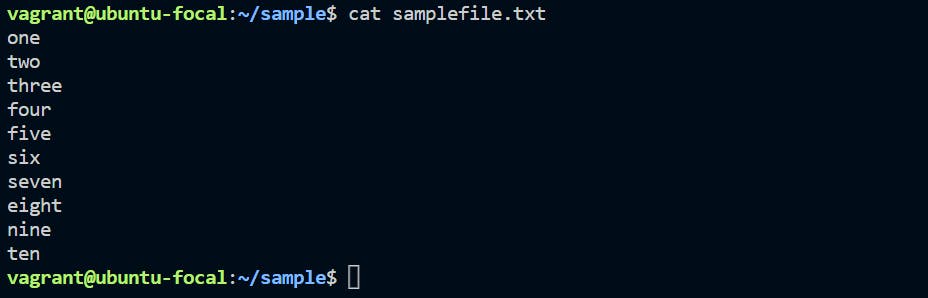
Execute cat samplefile.txt to see contents of an existing file "samplefile.txt".
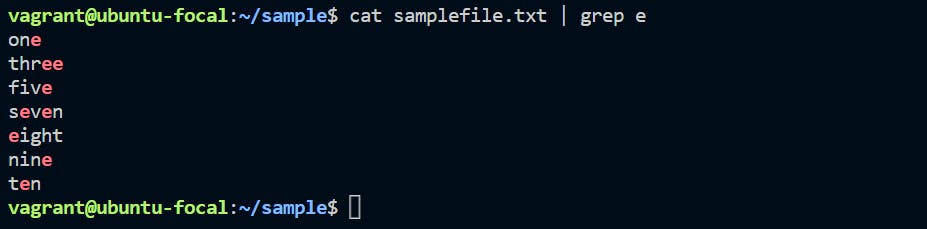
Search for content containing letter "e".
RegExp with ^ symbol
^ matches the start of a string. In the Linux regular expression, we are able to search the starting of the string associated using the ^ symbol. To search the string we need to use any text/string editor or searching algorithm.
Code:
cat samplefile.txt | grep ^t
Explanation:
We are having a sample directory, in the same directory there is filename “samplefile.txt”. There are records in it. We are using the samplefile.txt as an input to Linux regular expression. We need to identify the records that are starting with character “t”.
Output:

Only lines that start with character are filtered. Lines which do not contain the character "t" at the start are ignored.
RegExp with $ Symbol
$ matches the end of a string. In the Linux regular expression, we are able to search the ending of character or string associated with the $ symbol. To search the string, we need to use any text/string editor or searching algorithm.
Code:
cat samplefile.txt | grep e$
Explanation:
In the same directory, there is filename “samplefile.txt”. There are few records in it. We are using the samplefile.txt as an input to Linux regular expression $. We need to identify the records that are ending with character “e”.
Output
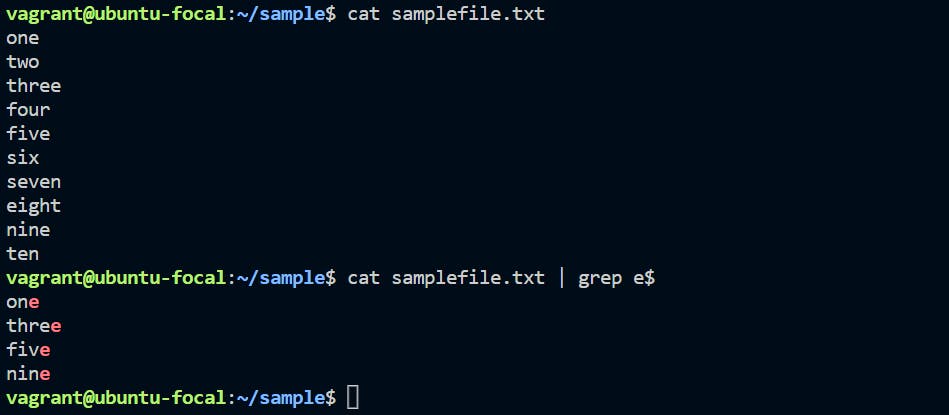
Only those lines that end with "e" are selected.
RegExp with * Symbol
In Linux regular expression, we are able to find or search the zero matches or more times matches in the preceding character. We need to use the * option with any text/string editor or searching algorithm.
Code:
grep "[AB]p*" file.txt
Explanation:
As per the above command, we are identifying the only “A” & “B” upper cases character and all character or string from the lowercase letter “p”. Accordingly, the given input we are able to get the relevant string from the input file.
Output:
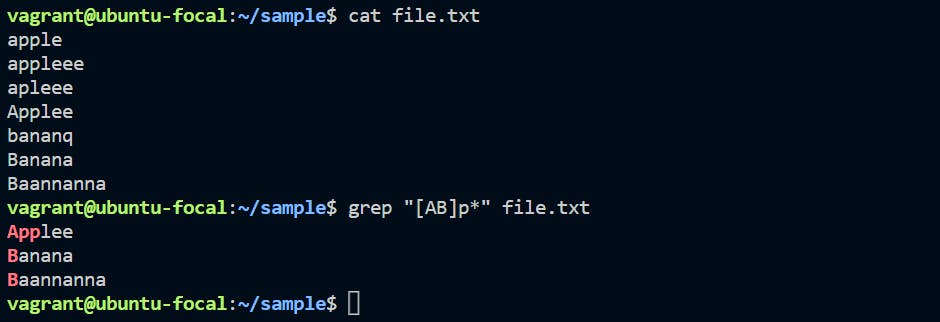
Note that grep "[AB]p*" file.txt can also be written as
cat file.txt | grep "[AB]p*"
2. Interval Regular Expressions
These expressions tell us about the number of occurrences of a character in a string. They are:
Expression: {n}
Description: Matches the preceding character appearing ‘n’ times exactly.
Expression: {n, m}
Description: Matches the preceding character appearing ‘n’ times but not more than m.
Expression: {n, }
Description: Matches the preceding character only when it appears ‘n’ times or more.
Let's look at some examples.
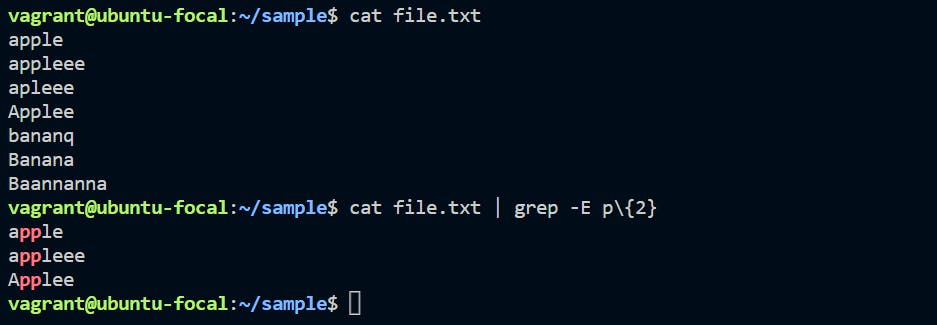
We want to check that the character ‘p’ appears exactly 2 times in a string one after the other. For this the syntax would be:
cat file.txt | grep -E p\{2}
or
grep -E p\{2} file.txt
In the Linux ecosystem, we are able to search the different combination of character. As per the above command, we are able to find the same sequence of character number of time as per the given value assign in the command. We are identifying the sequence of character “p” coming two times in the string.
Note: We need to use the “-E” option with the character/string interval value.
3. Extended Regular Expressions
These regular expressions contain combinations of more than one expression. Some of them are:
Expression Description
\+ Matches one or more occurrence of the previous character
\? Matches zero or one occurrence of the previous character
Examples:
RegEx with “+” symbol
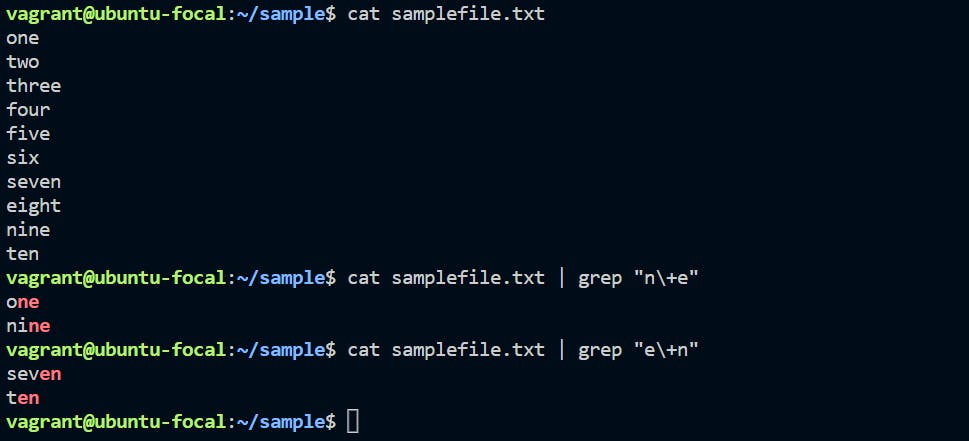
Suppose we want to filter out lines where character 'n' precedes character ‘e’ and where character 'e' precedes character ‘n’:
We can use command like
cat sample | grep "n\+e"
and
cat sample | grep "e\+n"
respectively.
Explanation:
We are using the input file as “samplefile.txt”. We need to search the string from starting character as “n” and adjutant character as “e”. As per the above commands, we are searching for a specific combination of characters from the input file.
Output:
RegEx with Separating Words
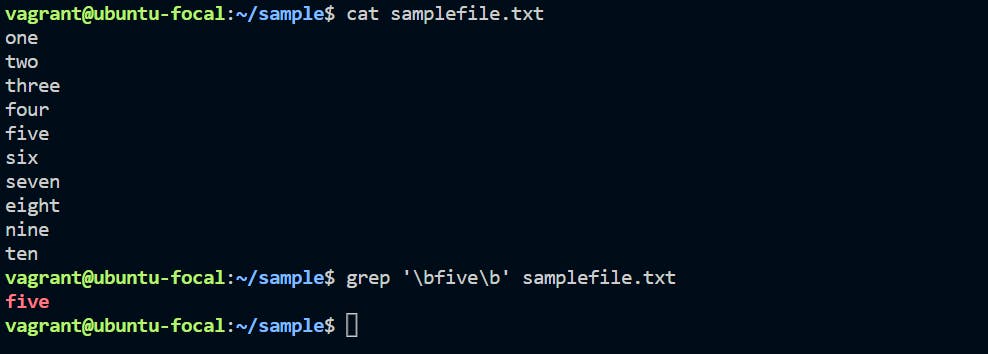
In the Linux Regular Expression, we are able to find the exact matching string from the input file. We need to use the “\b\b” option with any text/string editor or searching algorithm.
Code:
grep '\bfive\b' file.txt
Explanation:
In Linux regular expression, we are able to find a specific string or character from the input file/data. As per the above command, we specify regular expression to find the exact string. We are using “\b\b” option into which we need to keep the search string.
Output:
Expression with “\?” symbol
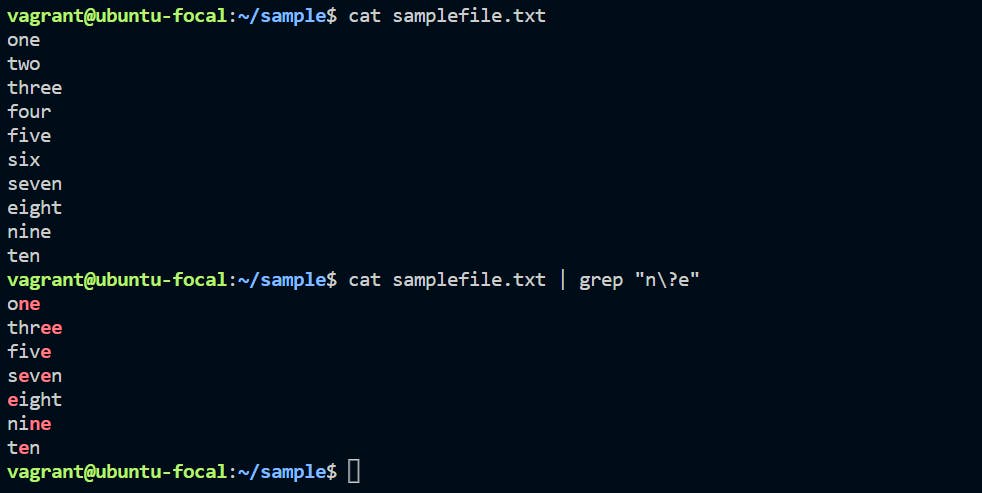
In the regular expression, we want to filter out the matches zero or more occurrences of the previous character from the input file.
Code:
cat file.txt | grep "n\?e"
Explanation:
We are using the input file as “samplefile.txt”. We need to search the string from starting character as “n” and adjutant character as “e”. As per the above command, we are searching a specific combination of characteristics from the input file and it will search all the character come under the input file.
Output:
Test for the Frequency of Occurrence
To further extend our skills in regular expressions, let's take a look at some more common special characters that allow us to look for not just matching text, but also patterns of matches.
Frequency Matching Characters:
CHARACTERS MEANING EXAMPLE
* Zero or more ab* – the letter a followed by
zero or more b's.
+ One or more ab+ – the letter a followed by one
or more b's.
? Zero or one ab? – zero or just one b.
{n} Given a number, find ab{2} – the letter a followed by
exactly that number exactly two b's.
{n,} Given a number, find ab{2,} – the letter a followed by
at least that number at least two b's.
{n,y} Given two numbers, find ab{1,3} – the letter a followed
a range of that number by between one and three b's.
Brace Expansion
The syntax for brace expansion is either a sequence or a comma separated list of items inside curly braces “{}”. The starting and ending items in a sequence are separated by two periods “..”.
Let's run through some examples:
silva@oluwaseunda-silva:~$ echo {aa, bb, cc, dd}
aa bb cc dd
silva@oluwaseunda-silva:~$ echo {0..11}
0 1 2 3 4 5 6 7 8 9 10 11
silva@oluwaseunda-silva:~$ echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
silva@oluwaseunda-silva:~$ echo a{0..9}b
a0b a1b a2b a3b a4b a5b a6b a7b a8b a9b
silva@oluwaseunda-silva:~$ |
As you can see, in the above examples, the echo command creates strings using the brace expansion.
Summary
- Regular expressions are a set of characters used to check patterns in strings
- They are also called ‘regexp’ and ‘regex’
- It is important to learn regular expressions for writing scripts
- Some basic regular expressions are:
Symbol Descriptions
. Replaces any character
^ Matches start of string
$ Matches end of string
- Some extended regular expressions are:
Expression Description
\+ Matches one or more occurrence of the previous character
\? Matches zero or one occurrence of the previous character
- Some interval regular expressions are:
Expression Description
{n} Matches the preceding character appearing ‘n’ times exactly
{n,m} Matches the preceding character appearing ‘n’ times but not more than m
{n, } Matches the preceding character only when it appears ‘n’ times or more
- The brace expansion is used to generate strings. It helps in creating multiple strings out of one.

Yes, that's a WOW!
I hope you liked this article. Please click on the like button below, and feel free to let me know in the comments what you think.
If you missed my previous article on Linux process management, you can always check it out here.
I also talk about #shellscripting, #pythonprogramming #linux, #cprogramming, #softwareengineering and #javascript. Please consider following me on Twitter and LinkedIn, and stay tuned for upcoming contents. ✒️.
Thank you for reading, I will see you in the next one.